
Digital
Masterless Puppet and Declarative provisioning
November 24, 2015 by craigmilligan No Comments | Category Digital Public Services, mygov.scot
This is a post by Gordon Clark, one of our Infrastructure Engineers, and Jono Ellis, our Social Media Manager.
This post is the second post in our series covering how we approach continuous delivery, covering the tools that we use.
We are not precious about our servers, they are just tools for a defined purpose and when they’ve reached the end of their usefulness we can get rid of them. They are disposable. This is something you can only do with cloud computing – we don’t own a physical server anywhere; instead we create and configure servers from our cloud providers. The benefits are the speed and agility that this setup offers us. As an example, in order to test a proof of concept we could spin up several servers to do a task, gather whatever stats we needed, and then we could destroy them. With no physical server needing to be purchased, set up, powered, etc. there are significant environmental benefits to this approach.
Tools
We use several tools in order to facilitate our server configuration management:
- Puppet – provisioning and configuration of hosts (we use Puppet in a masterless way);
- Packer – definition and creation of our base image;
- Base images – assignment of a role and an environment (based on the rules for the role a host is given, the host will self-provision. This means that the host gathers packages and configuration from a known artifact repository such as Debian);
- Vagrant – deploying Puppet runs locally for testing purposes.
Roles and Profiles
The role a server is provided with equates to a business need i.e. a web server, an application or a database server.
Each role (e.g. web server) has an accompanying module in Puppet. This Puppet module in turn contains one or more technology profiles, which are also described in Puppet. Each host can only be assigned a single role but each role can contain multiple profiles (which is turn can contain multiple modules). The modules are directly related to an individual technology, e.g. NGINX, Java or PostgreSQL. The diagram below shows how the hierarchy is arranged. It should be noted that the modules are generic, they can be used in any environment and do not contain any configuration related to an individual host. The configuration data is abstracted to Hiera.
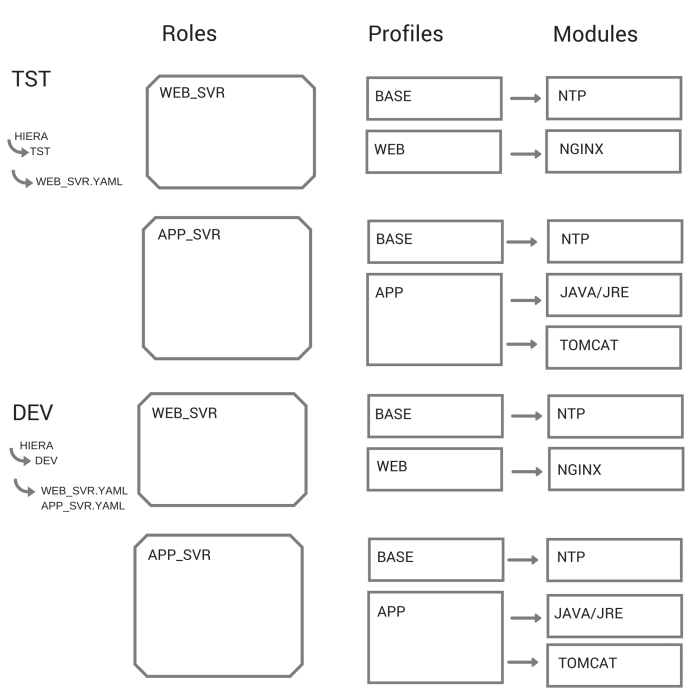
In addition to the role, each server is assigned to an environment (i.e. dev, test or production), and from that it picks up the appropriate state and configuration. We use Puppet because Puppet is good for saying what state something should be – what packages should be installed and how they can be configured.
The code below gives you an example of setting up the role of a web server which will be spun up with an Nginx profile.
Example role manifest: web_svr.pp
[code]
#- file: modules/role/manifests/web.pp
#- Class: role::web_svr
#
# Class to define a web server role
#
class role::web_svr {
include profile::base
include profile::web
}
[/code]
Example profile manifest: web.pp
[code]
#- file: modules/profile/manifests/web.pp
#- Class: profile::web
#
# Class to incorporate all web components
#
class profile::web {
class { ‘nginx’: }
}
[/code]
Example profile manifest: base.pp
[code]
#- file: modules/profile/manifests/base.pp
#- Class: profile::base
#
# Class to install the base requirements for any host
#
class profile::base {
package { “ntp”:
ensure => installed
}
service { “ntp”:
ensure => running,
require => Package[‘ntp’]
}
}
[/code]
We do things in the cloud but we’ve created some example code which will run on your own computer. At the end of this article we have included instructions and a link so that you can run this Puppet example on VirtualBox.
Configuration
A lot of our application configuration is externalised to the Hiera config repository as YAML files which contain the configuration. We have our Puppet modules which define technologies and Hiera config files which can contain things like port numbers, root directory, host name, etc. It’s a good idea to separate the Puppet modules from the Hiera config as this means that a module can be taken off the shelf and configured separately.
For example our environment/role configuration is arranged as follows in Hiera:
./dev/app_svr.yaml
./dev/web_svr.yaml
./tst/app_svr.yaml
./tst/web_svr.yaml
So, if a host is defined as a ‘dev’ ’web_svr’ (i.e. a development environment web server) then it inherits the values defined in the ./dev/web_svr.yaml file – in the provided files this means that the image displayed is a unicorn. If a host is defined as a ‘tst’ ’web_svr’ (i.e. a test environment web server) then it inherits the values defined in the ./tst/web_svr.yaml file – which means it uses the panda.png image.
The process we follow to apply our Puppet manifests/configuration is as follows:
- Puppet code checked in to Stash
- Packaged as a versioned Debian ‘deb’
- Pushed to Nexus and an apt repository
- Trigger Puppet run via Bamboo
- Package containing Puppet Module is pulled to individual boxes
- Installed
- Puppet Apply is run applying the new code/configuration
Why masterless?
- We don’t have to worry about certificates or scaling
- We can trigger a Puppet run across an entire environment
- We can version the Puppet manifests and promote them with the other code
We don’t have to worry about how to scale Puppet because it is self-contained and runs locally on the target box i.e. there is no Puppet master. We treat Puppet manifests as artifacts themselves so they can be tested and promoted through the pipeline accordingly. This agility comes into it’s own when news of a security vulnerability (such as Shellshock or Heartbleed) is announced online – we have the ability to make security updates quickly and with relative ease.
Many people use Puppet masters and both setups have their advantages, as do alternate setups using Chef or Ansible. We chose to go masterless as it was the best fit for us; we can version control Puppet, treat it like an artefact and orchestrate Puppet how we want. We are also not subject to scaling issues as there is no need for certificate agent. Any problem we can roll back or rebuild as appropriate.
Demo code
You can download and play around with our example following these steps:
- Download/clone our demo code from Github
- Install VirtualBox
- Install Vagrant
- Go to the ./puppettest directory & run the following:[code]vagrant up –provider=”virtualbox”[/code]
- This should provision 2 virtual machines on your local machine – 1 web server and 1 app server – provisioned as ‘dev’ environments.
- To change this to the ‘tst’ environment, simply modify the symbolic link ‘servers.yaml’ to link to ‘servers.yaml.tst’ by running:[code]rm –f servers.yaml[/code][code]ln -s servers.yaml.tst servers.yaml[/code]
Once the VM’s are up and running, open any browser and navigate to http://localhost:8080 for the web server and http://localhost:9090 for the app server (the servers.yaml file has details of what ports are forwarded).
Useful links
Roles and profiles:
- http://rnelson0.com/2014/07/14/intro-to-roles-and-profiles-with-puppet-and-hiera/
- http://garylarizza.com/blog/2014/02/17/puppet-workflow-part-2/
Masterless Puppet:
- http://pierrerambaud.com/blog/devops/using-hiera-with-puppet
- https://www.digitalocean.com/community/tutorials/how-to-set-up-a-masterless-puppet-environment-on-ubuntu-14-04
- https://puppetlabs.com/presentations/de-centralise-and-conquer-masterless-puppet-dynamic-environment
We’ll be sharing updates on this topic, and much more on social, so follow the team via @mygovscot on Twitter for more updates. Got a question or want to comment? Get in touch below!
Tags: Technology & Digital Architecture
Leave a comment