
Digital
Making our data machine readable
June 7, 2019 by Digital Identity Scotland No Comments | Category Content Design, Data, Digital Scotland, Uncategorized
The Data Standards team are based in Atlantic Quay in Glasgow and are working to improve the interoperability of public sector data by helping computers understand what our data means.
So much data and information is available to us everyday but it’s not always in a format that we, the public, or computers (that act on our behalf) can actually make use of. One of the biggest reasons for this is that our data is not understood by machines.
Think like a computer
When your computer opens a spreadsheet it has no idea what the columns and headings mean or how they relate to one another. All it sees are “strings” of letters and numbers.
It can read the text in each cell but it doesn’t understand what that text means.
We could ask the computer to find or match one piece of data to another, like searching for someone’s name, but we couldn’t ask it questions which require an understanding of the data’s meaning.
For example, “What is Jane’s surname?”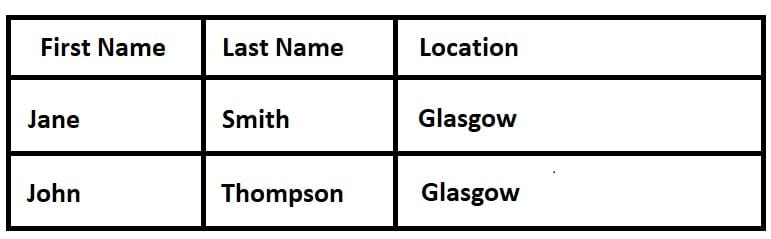
To answer this the computer would need to know that the information in column two relates to the person in column one, and that surname is a synonym for last name.
If we then asked, “Who lives in Scotland?”
The computer would also have no way of knowing that the text in the “Location” column refers to where the people in column one live. Even if it did, it couldn’t then know that Jane is from Glasgow, Scotland where as John is actually from Glasgow, Kentucky.
In its current form, the information above needs a lot of human interpretation to make sense of it.
Why do computers struggle with our language?
Language is a complex tool. We don’t always say what we mean, or mean what we say. We use things like imagery, sarcasm, humour and tone to change the meaning of our words. Just think of the Scottish classic, “Aye right”. This is a double positive which means a negative when delivered with a certain tone. How is a computer supposed to know what we mean?
One way to help remove this ambiguity and need for complex human interpretation, is to use unique identifiers for the things we tell a computer instead of text labels.
So rather than speaking about a “tree” and hoping that a computer understands we mean a family tree rather than a natural tree from the context, we can use an identifier that tells the computer exactly what type of tree we mean.
Why do computers need to understand?
Here’s one example.
With the rise of voice search tools like Alexa, Siri and Google, more and more people are asking questions of search engines which require computers to understand and interpret data in the way that a human would. If we asked one of these tools “When does the next ferry leave from Oban to Mull?”, the computer would have to understand:
– Oban and Mull are the names of places
– The geographical location of these places (and if there are multiple places with that name, which specific one are you likely to mean)
– That a ferry is a boat which carries people and cars over bodies of water
– Which companies run the ferry
– The current date and time
– That your question is asking for the time and date of departure which is closest to the time you have searched
That’s quite a lot of understanding for a simple question.
The ever increasing popularity of online searching means that many of the big search engine companies are working on ways to improve how data on the internet is understood and used by machines. The Data Standards project is tackling some of these same issues on behalf of the public sector.
Contact
If you would like to hear more about our work, keep an eye out for future blogs or get in touch with Sophie.Finlayson@gov.scot
Leave a comment